Ahoy!
An Android app for local message broadcasts.

Berlin Hack and Tell #23
Michael Specht
http://ahoy.nhcham.org
Political statements via SSID
http://opensignal.com/reports/politics-of-wifi-names.php
Ahoy - what's it about?
- you enter a message into your Android phone:
Look behind you, a three-headed monkey! - the app sets up a WiFi hotspot, using the
SSID to broadcast the message:
aR6Sg0VTH8VaDwcl9uHzNDFhvAfROR9 - everybody using the app within a range of ~30 meters receives your message
Possible scenario: Demonstrations

http://www.zeit.de/politik/ausland/2013-06/tuerkei-proteste-berichte
Possible scenario: Flood volunteers

Possible scenario: Sports events

Possible scenario: Live events

Ahoy SSID format
- SSID: 31 printable ASCII characters
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
0123456789 -_\|/,."'`(){}[]<>+#@%^!~*=$&?:; - better use alphanumerical characters only
- SSID format:
^a[0-9a-zA-Z]{30}$ - Capacity:
- log262 = 5.95 bits
- 30 ⋅ log262 = 178 bits
Ahoy SSID format
 How many different messages can we encode using 178 bits?
How many different messages can we encode using 178 bits?
383,123,885,216,472,214,589,586,756,787,577,295,904,684,780,545,900,544
- 178 bits ≈ 22 bytes → using UTF-8 or UTF-16:
- ~21 characters (Latin scripts)
- ~11 characters (Cyrillic, Arabic, Hebrew, Devanagari, Hangul, Hiragana, Katakana, Han, ...)
We're wasting a lot of bits there...
- each of these messages has the same cost (104 bits):
Hello, world!Hello, rmwqp/HellLwPrMwQp#Qq0dd9HLmsuhB- the fraction of meaningful messages is minimal

- → skew the message space in a way that makes:

- meaningful messages cheaper
- random noise more expensive
Huffman trees to the rescue!
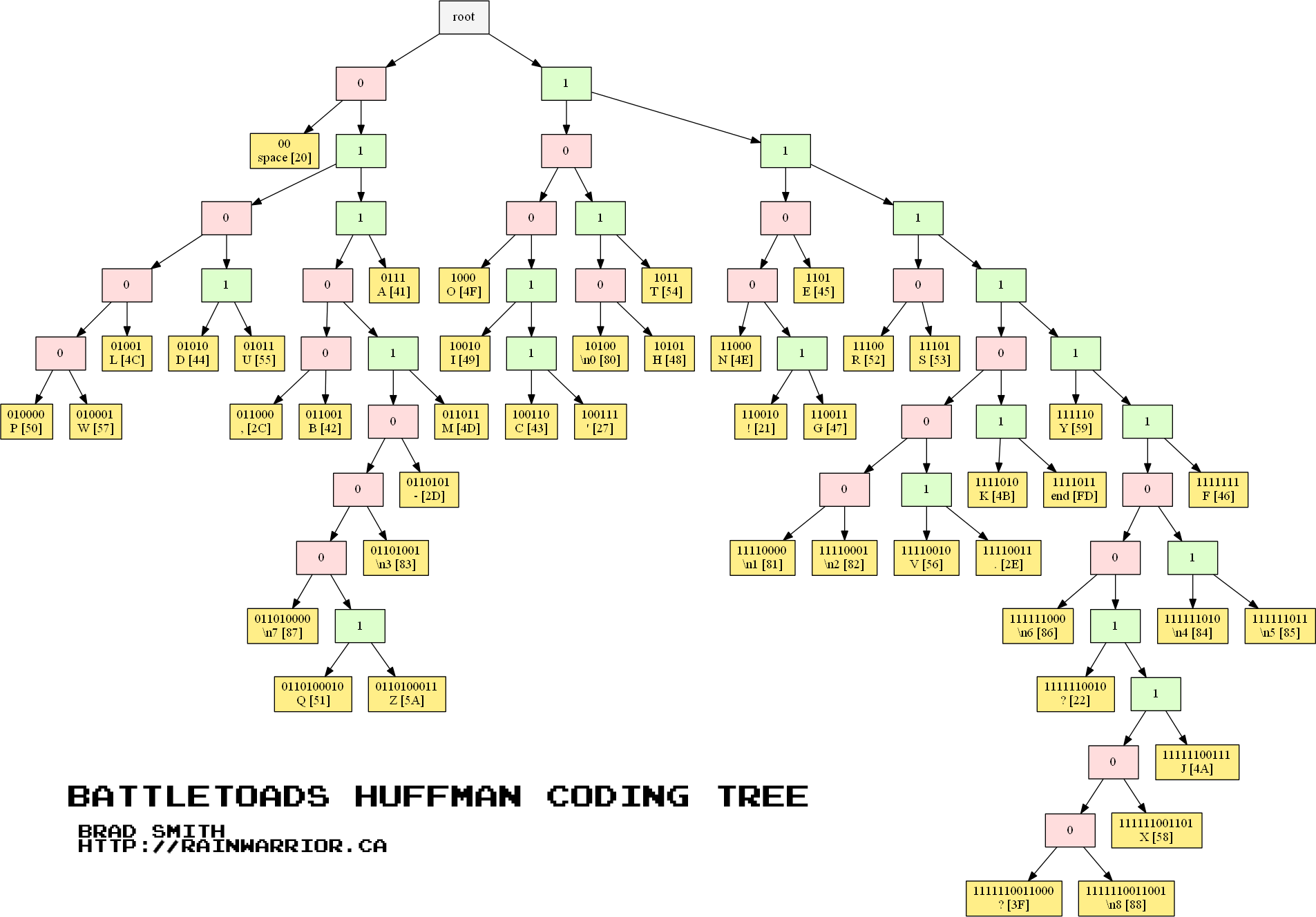

Huffman coding
- use character probabilities to:
- assign short bit strings to frequent characters
- assign longer bit strings to non-frequent characters
- we need a lot of text samples
- the Leipzig Corpora Collection provides real-world sample text in 80+ languages (10,000 or 100,000 sentences each)
Character probabilities
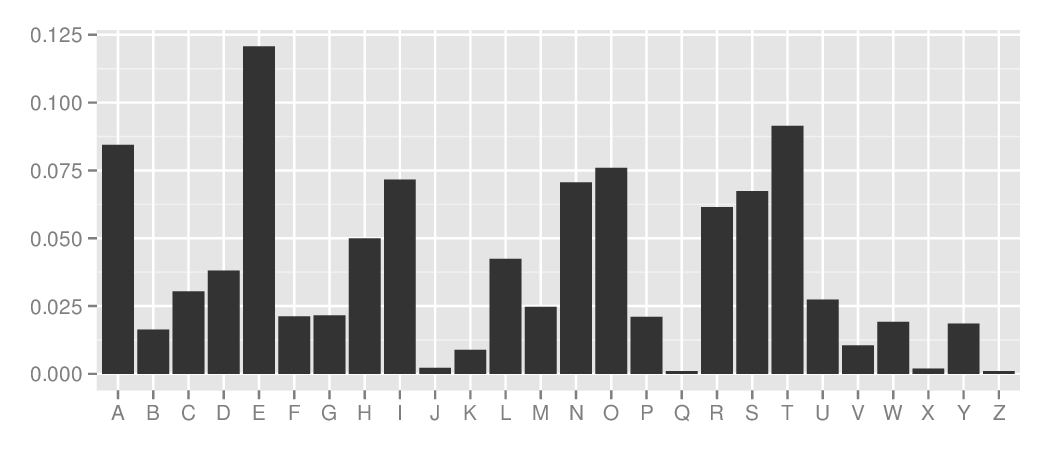 English
English
Character probabilities
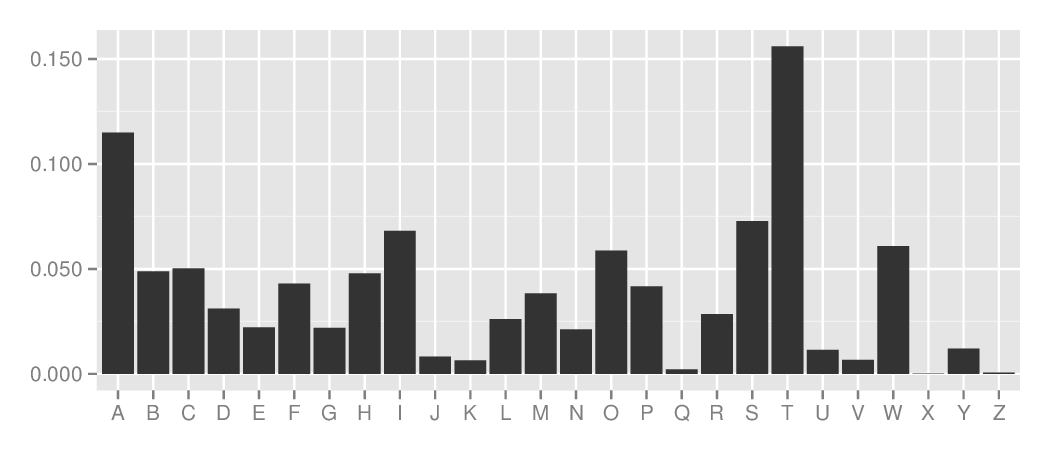 English, first letter in word
English, first letter in word
Character probabilities
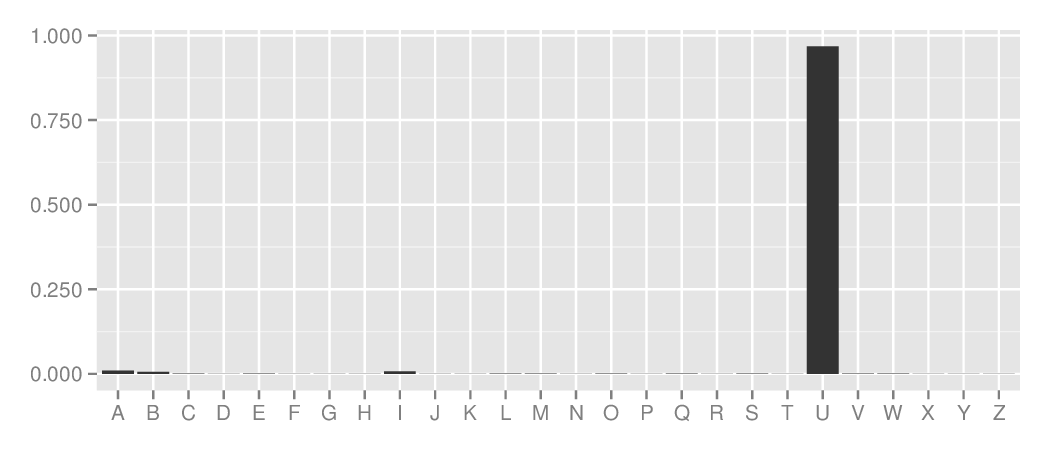 English, following Q
English, following Q
Character probabilities
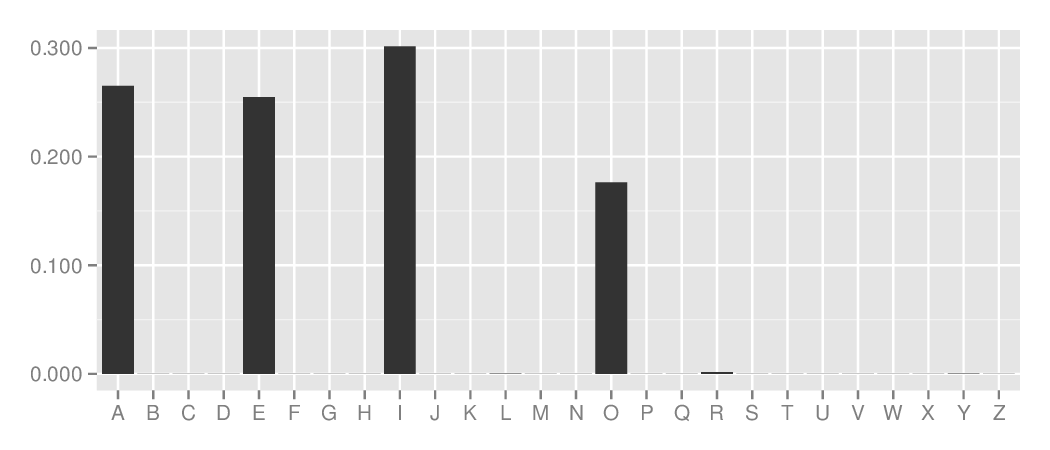 English, following QU
English, following QU
Context-sensitive Huffman coding
- natural language is highly context-sensitive
- create a lot of Huffman trees for various contexts:
- default tree
- word offset trees
- monogram prefix trees
- bigram prefix trees
- → 200 – 500 of the most used trees are chosen and stored as a language pack
- always use the most appropriate Huffman tree depending on the context during encoding/dedocing
Language packs
| Language | Trees | Size | UTF | Ahoy | ||
|---|---|---|---|---|---|---|
| English | English | 200 | 30.3 kB | 22 | 43 – 58 | 229% |
| German | Deutsch | 200 | 31.9 kB | 21 | 43 – 58 | 240% |
| Hebrew | עברית | 250 | 28.2 kB | 12 | 42 – 51 | 387% |
| Russian | русский | 300 | 41.4 kB | 12 | 41 – 55 | 400% |
| Persian | فارسی | 400 | 48.6 kB | 12 | 42 – 55 | 404% |
| Arabic | العربية | 300 | 44.7 kB | 12 | 43 – 55 | 408% |
| Hindi | हिन्दी | 400 | 49.5 kB | 11 | 41 – 56 | 440% |
| Korean | 한국어 | 50 | 151.4 kB | 10 | 23 – 30 | 265% |
Ahoy Demo
Typos: bad
Sometimes, typos make a message more expensive:


...even if the corrected message is longer!
Proper writing: good
Camel casing produces more expensive messages than proper writing:
Katzenfutter billig. Nur 1 € bei Kaisers. → 171 bits
KatzenfutterBillig.Nur1€BeiKaisers. → 194 bits
Thank you for listening!
